In bash you can set a variable to ‘readonly’. This can be very useful to prevent accidental overwrites.
readonly INSTALLDIR="/opt/goodSoftware"In bash you can set a variable to ‘readonly’. This can be very useful to prevent accidental overwrites.
readonly INSTALLDIR="/opt/goodSoftware"Im folgenden teile ich hier einige Gedanken zu dem Papier:
“Harmonisiertes Metadatenschema für die DSpace-Repositorien der Berliner Universitäten – Ergebnis der Arbeitsgruppe DSpace Metadaten bestehend aus Mitgliedern der Charité – Universitätsmedizin Berlin, der Freien Universität Berlin, der Humboldt-Universität zu Berlin und der Technischen Universität Berlin”
Zu finden hier: https://refubium.fu-berlin.de/handle/fub188/37260
Direktlink zum Datensatz hier: https://refubium.fu-berlin.de/bitstream/handle/fub188/37260/Berlin_DSpace_MDS.xlsx?sequence=1&isAllowed=y&save=y
Als Entwickler finde ich die im Abstract formulierten Zielsetzungen besonders wichtig und erfreulich:
“Ziel ist, innerhalb der Berliner Universitäten einen einheitlichen
Gebrauch der Metadaten zu gewährleisten. Gleichzeitig wird es bei
Einführung des neuen Modells möglich sein, Mappingtabellen, Schnittstellen
und Programmierarbeiten zwischen den beteiligten Einrichtungen leichter
auszutauschen.”
Trigger
Das Arbeitsergebnis wurde als Excel-Datei veröffentlicht. Dies reicht als Grundlage für einen gelungenen Datenaustausch natürlich noch nicht aus. Typische Folgefragen von Softwareentwicklern sind:
– Wo finde ich die konkreten Schemadateien?
– Gibt es Testsysteme?
– Welche Protokolle/APIs sollen zum Austausch der Daten angeboten und genutzt werden?
– Wie sieht es mit Mehrsprachigkeit in den Metadaten aus?
Aber zurück zum vorliegenden Datensatz:
Beobachtung
An vielen Stellen in der Excel-Datei steht als Datentyp Freitext. Es gibt kaum MetaMetadaten. An einigen Stellen erscheint das Modell zu flach und zu spezifisch. Dies ist in gewisser Weise Schade, da hier die zitierte. Zielsetzung möglicherweise durch “ein paar Handgriffe” optimaler unterstützt werden könnte.
Beispiel aus Zeile 22-24:
| Feld | Beispielwert |
| dc.subject | open access |
| dc.subject.ddc | 300 Sozialwissenschaften |
| dc.subject.rvk | AK 54355 |
Ein paar Dinge fallen hier auf:
1. In den Freitextfeldern werden Notationen und Label gemischt
2. Für einzelne Notationssyteme existieren spezielle Unterfelder (ddc,rvk). Dies ist nicht gut erweiterbar. Besser wäre es zu jedem Subject das Notationssystem zu vermerken und für diesen Vermerk seinerseits ein kontrolliertes Vokabular (z.B. basierend auf Wikidata, s.u.) zu definieren.
3. Es wird nicht ganz klar, wie Mehrsprachigkeit realisiert werden soll.
4. Es gibt kein (Sub)Feld indem z.B. URIs auf SKOS-Vokabulare mitgeführt werden könnten.
These
Um den Bereich “subject” besser maschinell nachnutzbar zu machen, sollten kontrollierte SKOS-Vokabulare die Regel sein. Wenn möglich sollten URIs zur Identifikation von verwendeten Termen mit im Datensatz gespeichert werden.
In jedem Fall sollten Notationen, Label und IDs im Datenmodell in getrennte Unterfelder laufen. Labels sollten mehrsprachig im Datensatz mitgeführt werden können bzw. über eine URI leicht nachgeladen werden können.
Beispiel und Vorschlag
Das Beispiel zeigt ein Schlagwort im Feld subject mit zusätzlichen Informationen.
"subject":[{
"id":"http://dewey.info/class/300",
"notation":"300",
"prefLabel": "Sozialwissenschaften",
"label":{
"de":"Sozialwissenschaften"
"en": "Social Sciences"
"fr":"...."
},
"source":{
"id":"https://www.wikidata.org/wiki/Q15222117",
"label":{
"en": "Dewey Decimal Classification"
}
"similarTo": "https://www.wikidata.org/wiki/Q34749"
}
}]
Zusätzlich zu dem Schlagwort werden Informationen zur Quelle und zum Notationssystem gegeben. Notation und Schlagwort werden getrennt. Es wird über einen Link auf Wikidata eine Verlinkung in andere Schlagwortsysteme realisiert.
Und was bringt das?
Dies hat vor allem Vorteile auf der maschinellen Konsumentenseite.
Blogpost for this stackoverflow answer: https://stackoverflow.com/a/74701083/1485527
Get code here
Create example app
npx create-react-app read-env-example --template typescript
Navigate to fresh app
cd read-env-example
Create Dockerfile
mkdir -p docker/build
docker/build/Dockerfile
# build environment
FROM node:19-alpine3.15 as builder
WORKDIR /app
ENV PATH /app/node_modules/.bin:$PATH
COPY package.json ./
COPY package-lock.json ./
RUN npm ci
RUN npm install react-scripts@5.0.1 -g
COPY . ./
RUN PUBLIC_URL="." npm run build
# production environment
FROM nginx:stable-alpine
COPY --from=builder /app/build /usr/share/nginx/html
EXPOSE 80
CMD ["nginx", "-g", "daemon off;"]
COPY docker/build/docker-entrypoint.sh /
RUN chmod +x docker-entrypoint.sh
ENTRYPOINT ["/docker-entrypoint.sh"]
Create docker-entrypoint.sh
This script will be executed at container start.
It generates the config.js file containing all environment variables starting with ‘MYAPP’ under window.extended.
docker/build/docker-entrypoint.sh
#!/bin/sh -eu
function generateConfigJs(){
echo "/*<![CDATA[*/";
echo "window.extended = window.extended || {};";
for i in `env | grep '^MYAPP'`
do
key=$(echo "$i" | cut -d"=" -f1);
val=$(echo "$i" | cut -d"=" -f2);
echo "window.extended.${key}='${val}' ;";
done
echo "/*]]>*/";
}
generateConfigJs > /usr/share/nginx/html/config.js
nginx -g "daemon off;"
Create docker-compose.yml
mkdir docker/run
docker/run/docker-compose.yml
version: "3.2"
services:
read-env-example:
image: read-env-example:0.1.0
ports:
- 80:80
env_file:
- myapp.env
Create runtime config for your app
docker/run/myapp.env
MYAPP_API_ENDPOINT='http://elasticsearch:9200'
Create config.js <– this is where .env will be injected.
public/config.js
/*<![CDATA[*/
window.extended = window.extended || {};
window.extended.MYAPP_API_ENDPOINT='http://localhost:9200';
/*]]>*/
Note: This file will be completely overwritten by the docker-entrypoint.sh. For development purposes you can set it to any value that is appropriate, e.g. when used together with npm start.
Include config.js in index.html
public/index.html
<head>
...
<script type="text/javascript" src="%PUBLIC_URL%/config.js" ></script>
...
</head>
<body>
Make use of your environment variable
src/App.tsx
declare global {
interface Window { extended: any; }
}
function App() {
return (
<div className="App">
<header className="App-header">
You have configured {window.extended.MYAPP_API_ENDPOINT}
</header>
</div>
);
}
Build
npm install
Create docker image
docker build -f docker/build/Dockerfile -t read-env-example:0.1.0 .
Run container
docker-compose -f ./docker/run/docker-compose.yml up
Navigate to your app
Open http://localhost in your browser.
You will see the content of MYAPP_API_ENDPOINT like provided in your docker/run/myapp.env.
Further usage
You can provide additional variables starting with MYAPP. The docker-entrypoint.sh script will search for all variables starting with MYAPP and make them available through the windows object.
For most people, the word “integration” creates the impression of connecting systems together, of sharing data to keep systems in sync. I believe that definition of integration is insufficient to meet the demands of a modern digital business, and that the real goal of integration done well is to create clean interfaces between capabilities.
At the example of this stackoverflow question:
“Supposing we have the following triple in Turtle syntax:
<http:/example.com/Paul> <http:/example.com/running> <http:/example.com/10miles> .
How do I add a start and end time? For example if I want to say he started at 10 am and finished his 10miles run at 12 am. I want to use xsd:dateTime.”
Sometimes it can be hard to create good, well fitting models. In my own experience it is crucial to identify a well defined set of entities and relations to create a vocabulary from. Some people prefer to use visual strategies to develop their models. I prefer to write models in structured text. This has the advantage that the process of modeling directly leads into actual coding.
Here is an example on how I would tackle the question .
1. The modelling part (not much RDF involved)
{
"runs": [
{
"id": "runs:0000001",
"distance": {
"length": 10.0,
"unit": "mile"
},
"time": {
"start": "2018-04-09T10:00:00",
"end": "2018-04-09T12:00:00"
},
"runner": {
"id": "runner:0000002",
"name": "Paul"
}
}
]
}
We store the json document in a file run.json. From here we can use the ‘oi’ command line tool , to create an adhoc context.
oi run.json -t contextThe resulting context is just a stub. But with a few additions we can easily create a context document to define id’s and types for each vocable/entity/relation.
2. The RDF part: define a proper context for your document.
{
"@context": {
"ical": "http://www.w3.org/2002/12/cal/ical#",
"xsd": "http://www.w3.org/2001/XMLSchema#",
"runs": {
"@id": "info:stack/49726990/runs/",
"@container": "@list"
},
"distance": {
"@id": "info:stack/49726990/distance"
},
"length": {
"@id": "info:stack/49726990/length",
"@type": "xsd:double"
},
"unit": {
"@id": "info:stack/49726990/unit"
},
"runner": {
"@id": "info:stack/49726990/runner/"
},
"name": {
"@id": "info:stack/49726990/name"
},
"time": {
"@id": "info:stack/49726990/time"
},
"start": {
"@id":"ical:dtstart",
"@type": "xsd:dateTime"
},
"end": {
"@id":"ical:dtend",
"@type": "xsd:dateTime"
},
"id": "@id"
}
}3. The fun part: Throw it to an RDF converter of your choice
This is how it looks in JSON-Playground
Or simply use ‘oi’:
oi run.json -f run.context -t ntriples
Prints:
_:b0 <info:stack/49726990/runs/> _:b3 .
_:b3 <http://www.w3.org/1999/02/22-rdf-syntax-ns#first> <info:stack/49726990/runs/0000001> .
_:b3 <http://www.w3.org/1999/02/22-rdf-syntax-ns#rest> <http://www.w3.org/1999/02/22-rdf-syntax-ns#nil> .
<info:stack/49726990/runs/0000001> <info:stack/49726990/distance> _:b1 .
<info:stack/49726990/runs/0000001> <info:stack/49726990/runner/> <info:stack/49726990/runner/0000002> .
<info:stack/49726990/runs/0000001> <info:stack/49726990/time> _:b2 .
_:b1 <info:stack/49726990/length> "1.0E1"^^<http://www.w3.org/2001/XMLSchema#double> .
_:b1 <info:stack/49726990/unit> "mile" .
<info:stack/49726990/runner/0000002> <info:stack/49726990/name> "Paul" .
_:b2 <http://www.w3.org/2002/12/cal/ical#dtend> "2018-04-09T12:00:00"^^<http://www.w3.org/2001/XMLSchema#dateTime> .
_:b2 <http://www.w3.org/2002/12/cal/ical#dtstart> "2018-04-09T10:00:00"^^<http://www.w3.org/2001/XMLSchema#dateTime> .
https://github.com/jschnasse/oi
wget https://dl.bintray.com/jschnasse/debian/oi_0.5.10.deb
sudo apt install ./oi_0.5.10.deb I use this docker-based approach.
0. Create a git repo to test this
mkdir my-git-project
cd my-git-project
git init
git commit --allow-empty -m"Initialize repo to showcase gitlab-runner locally."
1. Go to your git directory
cd my-git-project
2. Create a .gitlab-ci.yml
Example .gitlab-ci.yml
image: alpine
test:
script:
- echo "Hello Gitlab-Runner"
3. Create a docker container with your project dir mounted
docker run -d \
--name gitlab-runner \
--restart always \
-v $PWD:$PWD \
-v /var/run/docker.sock:/var/run/docker.sock \
gitlab/gitlab-runner:latest
4. Execute with
docker exec -it -w $PWD gitlab-runner gitlab-runner exec docker test
5. Prints
...
Executing "step_script" stage of the job script
$ echo "Hello Gitlab-Runner"
Hello Gitlab-Runner
Job succeeded
...
Note: The runner will only work on the commited state of your code base. Uncommited changes will be ignored. Exception: The .gitlab-ci.yml itself must not be commited to be taken into account.
_:b0 a <http://schema.org/Book> ;
<http://schema.org/name> "Semantic Web Primer (First Edition)" ;
<http://schema.org/offers> _:b1 ;
<http://schema.org/publisher> "Linked Data Tools" .
_:b1 a <http://schema.org/Offer> ;
<http://schema.org/price> "2.95" ;
<http://schema.org/priceCurrency> "USD" .Based on this stack overflow answer I created a tool named **oi** that provides some capabilities to convert rdf to json via command line. If no frame is provided via cli, the tool aims to generate @context entries for most situations.
oi -i turtle -t json books.ttl |jq '.["@graph"][0]'
prints
{
"@id" : "_:b0",
"@type" : "http://schema.org/Book",
"name" : "Semantic Web Primer (First Edition)",
"offers" : {
"@id" : "_:b1",
"@type" : "http://schema.org/Offer",
"price" : "2.95",
"priceCurrency" : "USD"
},
"publisher" : "Linked Data Tools"
}
The tool attempts to create various output formats. The result is not meant to be 100% correct for each and every case. The overall idea is to provide adhoc conversions just as one step in a conversion pipeline.
The tool is available as .deb package via it’s github page at: https://github.com/jschnasse/oi.
How to create a java command line tool that is (1) easy to install (2) as small as possible (3) and does not interfere with a previously installed jvm on the host?
.deb packageAll snippes were taken from https://github.com/jschnasse/oi
The oi command line app is a very simple conversion tool to transform structured formats from one into another.
I use the maven-assembly-plugin for this. Here is the relevant section from my pom.xml.
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
<configuration>
<finalName>oi</finalName>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>org.schnasse.oi.main.Main</mainClass>
</manifest>
<manifestEntries>
<Automatic-Module-Name>org.schnasse.oi</Automatic-Module-Name>
</manifestEntries>
</archive>
<appendAssemblyId>false</appendAssemblyId>
</configuration>
</plugin>
The most important configuration entry is the path to the <mainClass> . The entry points to a java class that must define a main method.
It also is important to define a fixed <finalName>. We don’t want to create artifacts with version numbers in it. The versioning is done elsewhere. Our build process should just spit out an executable at a predictable location.
The mvn package command will now create a fat jar under target/oi.jar.
The created jar can be executed as java -jar target/oi.jar. This is already an important milestone since you can now use the app on your own development pc. To make it a bit handier put the actual call into a script and copy it to /usr/bin/oi in order to make it accessible for all users on the development machine. Also you can provide the oi.jar at a more global location, e.g. /usr/lib.
This could be the content of /usr/bin/oi
java -jar /usr/lib/oi.jar $@
Use $@ to pass parameters from command line to the actual java app.
More on this will be explained in the ‘Package everything together’ section.
The next step is to make the program executable on other machines. Since the application depends on the existence of the java interpreter we have to find a way to either ship java together with our little oi tool or to ask the user/user’s computer to install it in advance.
Both approaches are feasible. I decided to ship java together with my tool for the following reasons (1) The tool should be as self contained as possible (2) The installation of the tool should not interfere with other java based packages. (3) I want to be free to update to new jvm versions at my own speed, therefore I want support only one single jvm version at every state of development.
Today java distributions come with a tool named jlink. The jlinktool can be used to create minimal jvms. This will look like:
jlink \
--add-modules java.base,java.naming,java.xml \
--verbose \
--strip-debug \
--compress=1 \
--no-header-files \
--no-man-pages \
--output /opt/jvm_for_oi
The result is a minimal jvm only containing the modules java.base,java.naming,java.xml under /opt/jvm_for_oi. The idea is now to provide this jvm together with our app. But to become a bit more independent from the configuration of my development machine I want to guarantee that my tool is served always with a well defined jvm version and not just with the version I have installed at my development machine. To create a well defined build environment I will use docker. With docker I can create a minimal jvm on the basis of a predefined openJDK version. And here is how it works.
1. Based on the code above we can create a file named Dockerfile.build to create the jvm based on the openJdk-12.0.1_12.
FROM adoptopenjdk/openjdk12:jdk-12.0.1_12
RUN jlink \
--add-modules java.base,java.naming,java.xml \
--verbose \
--strip-debug \
--compress 2 \
--no-header-files \
--no-man-pages \
--output /opt/jvm_for_oi
We will use this docker definition just to create the jvm and copy it to our development environment. The docker image can be deleted directly afterwards.
docker build -t adopt_jdk_image -f Dockerfile.build . docker create --name adopt_jdk_container adopt_jdk_image docker cp adopt_jdk_container:/opt/jvm_for_oi /usr/share/jvm_for_oi docker rm adopt_jdk_container
The resulting jvm can be found under /usr/share/jvm_for_oi.
This again is a very important milestone. You can now edit your startscript at /usr/bin/oi and use the generated jvm instead of your preinstalled java version. This will make the execution of the app independent of the globally installed java version and therefor more reliable.
/usr/share/jvm_for_oi/bin/java -jar /usr/lib/oi.jar $@
In my project configuration the inclusion of the minimal jvm increases the size of the .deb package by ~10MB. On the target system the jvm takes ~45MB extra space. In my former setup I configured openJDK-11 as dependency in the Debian package which consumes roughly ~80MB of extra space if newly installed.
Since oi is a java app built with maven I use the typical semantic versioning scheme which consists of three numbers (1) a major, (2) a minor, (3 ) and a patch number divided by dots. Example given, a version of ‘0.1.4’ reads as follows:
0 – No major version. There is no stable version yet. Development is still at an early stage.
1 – First minor version. This is software at an very early stage. Usually minor versions are compatible to the recent major release. Since no major version exists this software has no reliable behavior yet.
4 – There were four patches released for the first minor version. A patch is typically a bug fix that does not change the
The process of creating a new version is done as the following. (1) Define the next Version in a variable oi_version stored in a file VERSIONS. (2) Use a script bumpVersions.sh to update the version numbers in several files like README, manpage, etc. (3) Commit files that were updated with the new version number to git. (4) Use the mvn-gitflow plugin to create new versions for the actual source and to push everything in a well defined manner to github.
<plugin>
<groupId>com.amashchenko.maven.plugin</groupId>
<artifactId>gitflow-maven-plugin</artifactId>
<version>1.7.0</version>
<configuration>
<gitFlowConfig>
<developmentBranch>master</developmentBranch>
</gitFlowConfig>
</configuration>
</plugin>
The gitflow-maven-plugin supports the command mvn gitflow:release . The command does the following:
1. Define a new release number
2. Update the pom.xml in the development branch accordingly
3. Push the updated pom.xml to the mainline branch
4. Create a tag on mainline
5. Update the release number in the development branch to a new SNAPSHOT release.
6. Push the updated pom.xml to the development branch.
The plugin was originally created with for the `gitflow` branching approach. Since my project uses the github-flow-branching approach which does not foresee a development branch besides of the mainline I defined master as development branch.
At this point a new release of the sourcecode is online at github. Now, it’s time to create the binary release. The binary release will be a .deb file containing the newly packaged fat-jar together with the minimal jvm. (5) A build.sh script is used to create the .deb artifact.
#! /bin/bash
scriptdir="$( cd "$( dirname "${BASH_SOURCE[0]}" )" && pwd )"
cd $scriptdir
source VERSIONS
mvnparam=$1
function build_oi(){
package_name=$1
package_version=$2
package=${package_name}_$package_version
mkdir -p deb/$package/usr/lib
mkdir -p deb/$package/usr/bin
mkdir -p deb/$package/usr/share/man/man1/
mvn package -D$mvnparam
sudo cp src/main/resources/$package_name deb/$package/usr/bin
sudo cp target/$package_name.jar deb/$package/usr/lib
docker build -t adopt_jdk_image -f Dockerfile.build .
docker create --name adopt_jdk_container adopt_jdk_image
docker cp adopt_jdk_container:/opt/jvm_for_oi deb/$package/usr/share/jvm_for_oi
docker rm adopt_jdk_container
ln -s ../share/jvm_for_oi/bin/java deb/$package/usr/bin/jvm_for_oi
}
function build(){
package_name=$1
package_version=$2
package=${package_name}_$package_version
if [ -d $scriptdir/man/$package_name ]
then
cd $scriptdir/man/$package_name
asciidoctor -b manpage man.adoc
cd -
sudo cp $scriptdir/man/$package_name/$package_name.1 deb/$package/usr/share/man/man1/
fi
dpkg-deb --build deb/$package
}
build_oi oi $oi_version
What you can see from the listing is that the script creates a directory structure in accordance to the .deb package format. It also generates (1) the fat-jar, (2) the minimal jvm (3) a man page and (4) binds it all together with a dpkg-deb -build command
(6) The .deb artifact is then uploaded to a bintray repo using again a shell script
#! /bin/bash
scriptdir="$( cd "$( dirname "${BASH_SOURCE[0]}" )" && pwd )"
source VERSIONS
function push_to_bintray(){
cd $scriptdir
PACKAGE=$1
VERSION=$2
API_AUTH=$3
subject=jschnasse
repo=debian
filepath=${PACKAGE}_${VERSION}.deb
curl -u$API_AUTH -XPOST "https://bintray.com/api/v1/packages/$subject/$repo/" -d@bintray/${PACKAGE}/package.json -H"content-type:application/json"
curl -u$API_AUTH -XPOST "https://bintray.com/api/v1/packages/$subject/$repo/$PACKAGE/versions" -d@bintray/${PACKAGE}/version.json -H"content-type:application/json"
curl -u$API_AUTH -T deb/$filepath "https://bintray.com/api/v1/content/$subject/$repo/$PACKAGE/$VERSION/$filepath;deb_distribution=buster;deb_component=main;deb_architecture=all;publish=1;override=1;"
curl -u$API_AUTH -XPUT "https://bintray.com/api/ui/artifact/$subject/$repo/$filepath" -d'{"list_in_downloads":true}' -H"content-type:application/json"
cd -
}
apiauth=$1
push_to_bintray oi $oi_version $apiauth
push_to_bintray lscsv $lscsv_version $apiauth
push_to_bintray libprocname $libprocname_version $apiauth
The script makes use of a set of prepared json files to provide metadata for the package.
(7) The last step is now to visit the github wegpage an navigate to the tag that has been created at step (4). By adding a release name it will become visible as release at the landing page of the git repo.
Step 6 seems the most critical step since it updates the debian repo and makes the new version available to everyone. In between step 5 and step 6 some sort of testing should happen to ensure that the artifact is installable and does execute as expected. My plan is to utilize a set of docker files to test releases. A first attempt can be found here.
The process of versioning consists of multiple steps. Most of the work can be automated. A semi automated process can be developed with little effort. To automate the whole process it is crucial to provide well thought tests in between the steps and to define fallback points. This adds some extra safety to the objective but also introduces extra complexity. For future jdk versions it could be beneficial to use jpackager instead of jlink.
With adhoc rdf generation from various formats.
less src/test/resources/json/in/rosenmontag.json oi src/test/resources/json/in/rosenmontag.json -trdf less src/test/resources/yml/in/HT015847062.yml oi src/test/resources/yml/in/HT015847062.yml -trdf|less
 Install
Install
wget https://dl.bintray.com/jschnasse/debian/oi_0.4.2.deb
sudo apt install ./oi_0.4.2.deb #depends on openjdk-11-jreWith pretty rdf printing support.
cat src/test/resources/rdf/context/stack43638342.rdf.context cat src/test/resources/rdf/in/stack43638342.rdf oi -i turtle -f src/test/resources/rdf/context/stack43638342.rdf.context src/test/resources/rdf/in/stack43638342.rdf

Install
wget https://dl.bintray.com/jschnasse/debian/oi_0.4.2.deb
sudo apt install ./oi_0.4.2.deb #depends on openjdk-11-jrehttps://github.com/jschnasse/oi
I always like this practical insights:
https://daniel.haxx.se/blog/2020/11/09/this-is-how-i-git/
Exclusively use git via console with modified prompt. Same here!
scm_info(){
git_info=`git branch 2>/dev/null | sed -e '/^[^*]/d' -e 's/* \(.*\)/\1/'`
if [ "${git_info}" ]; then
if [ "$(git status -s)" ]; then
git_color='\033[1;31m'
else
git_color='\033[1;36m'
fi
echo -e "${git_color}git:${git_info}"
fi
}
PS1='\n\[\033[1;32m\][\w] $(scm_info)\[\033[0m\]\n\$ '
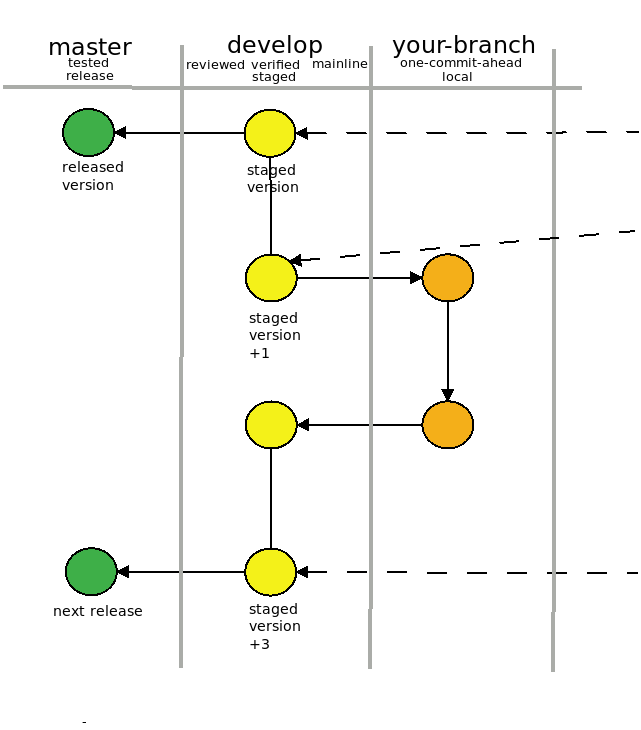
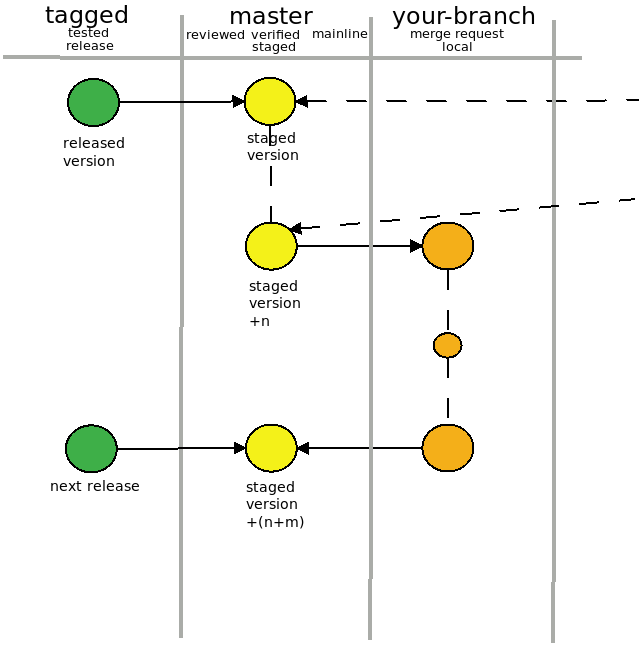
My advice for beginners is: 1. Do not hesitate to bring all sort of command line tools into position. Git offers nice tools for many situations but you don’t have to use them all. 2. Branch, Branch, Branch – it will help you to go back.
1. There is only one user interaction – it is called “the Request”. Please forget about GET,POST,PUT,DELETE. It is just “the request”. The request in general is not of your concern. Everything is handled by the framework. You don’t have to write controller code. In fact, you can not! The controller is already there. It is called “FacesServlet”.
2. The Framework handles all aspects of HTTP with “the request lifecycle”.
3. You have to learn the request lifecycle.
Advantages
Disadvantages
oi 0.3.0 comes with enhanced XML support.
I started a debian repo at bintray, mostly for fun stuff and own usage. Don’t expect more than random stuff.
Accept the bintray gpg key.
curl -sSL \
'https://keyserver.ubuntu.com/pks/lookup?op=get&search=0x379ce192d401ab61' \
| sudo apt-key add -
Add my repo
echo "deb https://dl.bintray.com/jschnasse/debian buster main" | sudo tee -a /etc/apt/sources.list.d/jschnasse.list
sudo apt update